Reviewing the definition of timbre as it pertains to the perception of speech and musical sound - ISH 2009
From CNBH Acoustic Scale Wiki
Patterson, R. D., Walters, T. C., Monaghan, J. J. M. and Gaudrain, E. (2010). “Reviewing the definition of timbre as it pertains to the perception of speech and musical sounds,” In: The neurophysiological bases of auditory perception. Lopez-Poveda, E.A., Palmer, A.R., Meddis, R. (eds.), New York, Springer, 223-233.
Below is the version of the paper as it was submitted to the conference organizers at the time of registration (January, 2009).
Contents |
Reviewing the definition of timbre as it pertains to the perception of speech and musical sounds
The purpose of this paper is to draw attention to the definition of timbre as it pertains to the vowels of speech. There are two forms of size information in these 'source-filter' sounds, information about the size of the excitation mechanism (the vocal folds), and information about the size of the resonators in the vocal tract that filter the excitation before it is projected into the air. The current definitions of pitch and timbre treat the two forms of size information differently. In this paper, we argue that the perception of speech sounds by humans suggests that the definition of timbre would be more useful if it grouped the size variables together and separated the pair of them from the remaining properties of these sounds.
Timbre, speech sounds and acoustical scale
"Timbre is that attribute of auditory sensation in terms of which a listener can judge that two sounds similarly presented and having the same loudness and pitch are dissimilar." ["American national standard acoustical terminology" (1994). American National Standards Institute, ANSI S1.1-1994 (R1999)]
Informally, the standard definition of timbre is regarded with considerable amusement. You might expect the definition of timbre to tell you something about what timbre is, but all the definition tells you is that there are a few things that timbre is not. It is not pitch, it is not loudness, and it is not duration. It is everything else. Despite the poverty of the definition, it appears in most popular introductory books on hearing and auditory perception, and aside from the definition, these books actually have rather little to say on the topic of timbre. This is somewhat surprising given how important the concept is in music and speech perception. Timbre is what distinguishes a trumpet from a violin when they are playing the same sustained note at the same loudness and for the same duration, and timbre is what distinguishes vowels spoken by a person on the same note at the same loudness and for the same duration. It is a very important concept in hearing and it is, perhaps, time to consider revising the definition of timbre, at least as it pertains to vocal sounds, to make it conform more with what we hear.
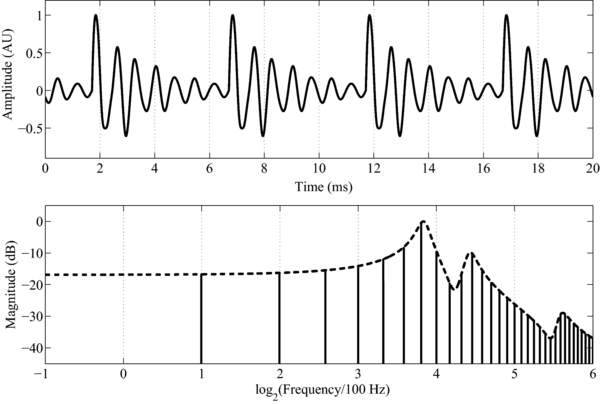
The aspects of timbre that are important in this paper are readily illustrated with the sustained sounds of speech, that is, sustained vowels. The waveform and spectrum of a short segment of a synthetic /a/ vowel, like that spoken by a child, are presented in the upper and lower panels of Figure 1, respectively. The waveform shows that a vowel is a stream of glottal pulses, each of which is accompanied by a decaying resonance that reflects the filtering of the vocal tract above the larynx. In this case, the glottal pulse rate (GPR) is 200 pulses per second (pps), so the time between glottal pulses (the period of the wave) is 5 ms. The set of vertical lines in the lower panel of Figure 1 shows the long-term magnitude spectrum of the sound, and the dashed line connecting the tops of the vertical lines shows the spectral envelope of the vowel. The peaky structures in the spectral envelope are the formants of the vowel; the shape of the envelope in the spectral domain corresponds to the shape of the damped resonance in the time domain.
When children begin to speak they are about 0.85 m tall and as they mature their height increases by about a factor of two. Vocal tract length increases in proportion with height (Fitch and Giedd, 1999; Turner et al., 2009 , Fig. 4), and so the formant frequencies of children's vowels decrease by about an octave as they mature (Lee et al., 1999; Turner et al., 2009). It is also the case that the GPR of the voice decreases by, on the order of, an octave as the vocal cords become longer and more massive, although the effect is more pronounced in males than in females. These effects are simple examples of the fact that larger objects vibrate more slowly than smaller objects; see Patterson et al. (2008) for examples from speech and music. In speech, the pattern of formants that defines a given vowel type remains largely unchanged as people grow up (Peterson and Barney, 1952; Lee et al., 1999; Turner et al., 2009). The effect of growth on the spectrum of a vowel is quite simple to characterize, provided the spectrum is plotted on a logarithmic frequency scale. In this case, the set of harmonics that define the fine structure of the spectrum simply moves, as a unit, towards the origin as the child matures into an adult, by about one octave. Similarly, the spectral envelope shifts towards the origin without changing shape, and it shifts during maturation by about an octave.
In acoustical terms, 'the position of the fine-structure of the spectrum on a logarithmic frequency scale' is the acoustic scale of the sound produced by the source of excitation; it is a property of the sound as it occurs in the air (Cohen, 1993) - a property that in this case is determined by the Glottal Pulse Rate (GPR) of the speaker. For brevity, it will be referred to as 'the scale (S) of the source (s)' and designated Ss. Similarly, in acoustical terms, 'the position of the envelope on a logarithmic frequency scale' is the acoustic scale of the filter in the vocal tract that produces the formants in the spectrum; it is also a property of the sound but in this case it is largely determined by the speaker's vocal tract length (VTL). For brevity, it will be referred to as 'the scale (S) of the filter (f)' and designated Sf. Turner et al. (2009) have recently reanalysed several large databases of spoken vowels and shown that almost all of the variability in formant frequency data is either attributable to vowel type (80%) or Sf (16%). The vocoder STRAIGHT (Kawahara and Irino, 2004) can be used to manipulate the acoustic scale variables independently and produce versions of notes with a wide range of combinations of Ss and Sf.
Timbre and the perception of speech sounds
The logic of the definition of timbre involves taking variables of auditory perception that appear to be associated with physical properties of sound, and separating them from other variables, which by default remain part of timbre; the perceptual variables that the definition encompasses are duration, loudness and pitch. Duration is the variable that is most obviously separable from timbre, and it illustrates the logic underlying the definition of timbre. If a singer holds a note for a longer rather than a shorter period, it produces a discriminable change in the sound but it is not a change in timbre. Duration has no effect on the magnitude spectrum of a sound, once the duration is well beyond that of the temporal window used to produce the magnitude spectrum. Since the current example involves sustained vowels and the window used to produce the magnitude spectrum in Figure 1 is on the order of 50 ms, duration has no effect on timbre in this example. In general, the perceptual change associated with a change in the duration of a sustained note is separable from changes in the timbre of the note.
Loudness is also largely separable from timbre. If we turn up the volume control when playing a recording, the change will be perceived as an increase solely in loudness. The pitch of any given vowel and the timbre of that vowel will be essentially unaffected by the manipulation. The increase in intensity produces a change in the magnitude spectrum of the vowel - both the fine structure and the envelope shift vertically upwards - but there is no change in the frequencies of the components of the fine structure and there is no change in the relative amplitudes of the harmonics. Nor is there any change in the shape of the spectral envelope. So, loudness is also separable from timbre.
This illustrates the logic behind the definition of timbre; acoustic variables that do not affect either the fine structure or the envelope of the magnitude spectrum do not affect the timbre of the sound. The question is 'What happens when a simple shift is applied to the position of the fine structure or the envelope of a sound, that is, when we change Ss, Sf, or both?' The current definition of timbre suggests that a change Ss, which is heard as a change in pitch, does not affect the timbre of the sound, whereas a change in Sf, which is heard as a change in speaker size, does affect the timbre. This is where the current definition of timbre becomes problematic.
Note, in passing, that shifting the fine structure of the magnitude spectrum while holding the envelope fixed produces large changes in the relative amplitudes of the harmonics as they move through the region of a formant peak. So the relative magnitude of the components in the spectrum can change substantially without producing a change in timbre, by the current definition. Note, also, that shifting the envelope of the magnitude spectrum while holding the fine-structure frequencies fixed produces similarly large changes in the relative amplitudes of the components as they move through formant regions. Shifting the envelope does not change the perceived vowel-type; nevertheless, these spectral changes are considered to produce timbre changes, by the current definition.
Timbre in the perception of 'acoustic scale melodies'
The timbre issues in the remainder of the paper are more readily understood when presented in terms of 'melodies' in which the acoustic scale values of the notes (Ss and Sf) vary according to the diatonic scale of Western music. The melodies are shown in Figure 2; all of them have four bars containing a total of eight notes. The melodies are in ¾ time, with the fourth and eight notes extended to give the sequence a musical feel. The black and grey notes show the progression of intervals for Ss and Sf, respectively, as the melody proceeds. The Ss component of the melodies is presented in the key of C major as it is the simplest to read. The melodies in the demonstration waves are actually in the key of G major.

Melody 1. The first example simulates a normal melody in which the VTL of the singer, and thus Sf, is fixed (grey notes), and the GPR, and thus Ss, varies (black notes). The singer is an adult male and the pitch of the voice drops by an octave over the course of the melody from about 200 to 100 pps [Figure 2, Staff (1)]. This descending melody is within the normal range for a tenor, and the melody sounds natural. The melody is presented as a sequence of syllables to emphasize the speech-like qualities of the source; the 'libretto' is 'pi, pe, ko, kuuu; ni, ne, mo, muuu.' In auditory terms, this phonological song is a complex sequence of distinctive timbres produced by a sequence of different spectral envelope shapes. The timbre changes engage the phonological system and emphasize the role of envelope shape in producing the libretto of the melody. As the melody proceeds, the fine-structure of the spectrum (Ss) shifts, as a unit, with each change in GPR, and over the course of the melody, it shifts an octave towards the origin. The definition of timbre indicates that these relatively large GPR changes, which produce large pitch changes, do not produce timbre changes, and this seems correct in this case. This suggests that pitch is largely separable from timbre, much as duration and loudness are, and much as the definition of timbre implies.
Melody 2. But problems arise when we extend the example with the help of STRAIGHT and synthesize a version of the same melody but with a singer that has a much shorter VTL, like that of a small child [Figure 2, Staff (2)]. There is no problem at the start of the melody; it just sounds like a child singing the melody. The starting pulse rate is low for the voice of a small child but not impossibly so. As the melody proceeds, however, the pitch decreases by a full octave, which is beyond the normal range for a child. In this case, the voice quality seems to change and the child comes to sound rather more like a dwarf. The ANSI definition of timbre suggests that the voice quality change from a child to a dwarf is not a timbre change, it is just a pitch change. But traditionally, voice quality changes are thought to be timbre changes. This is the first form of problem with the standard definition of timbre - changes that are nominally pitch changes producing what would normally be classified as a timbre change.
Melody 3. The next example [Figure 2, Staff (3)] involves reversing the roles of the variables Ss and Sf, and using STRAIGHT to manipulate the position of the spectral envelope, Sf, while holding Ss, and thus the pitch, fixed. Over the course of the melody, the position of the envelope, Sf, shifts by an octave towards the origin. This simulates a doubling of the singer's VTL, from about 10 to 20 cm. As with the previous Ss melodies, the specific values of Sf are determined by the diatonic musical scale of Western music. In other words, the sequence of Sf ratios have the same numerical values as the sequence of Ss ratios used to produce the first two melodies. This effectively extends the domain of notes from a diatonic musical scale to a diatonic musical plane, like that illustrated in Figure 3. The abscissa of the plane is Ss or GPR; the ordinate is Sf or VTL. Both of the axes are logarithmic.
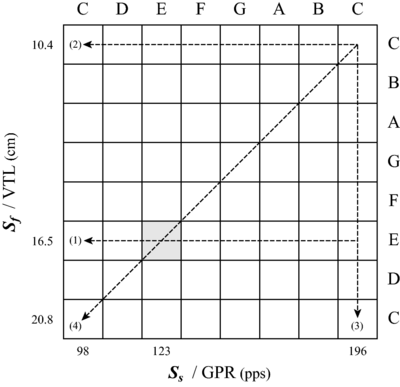
The syllables of the libretto were originally spoken by an adult male (author RP) with a VTL of about 16.5 cm and an average GPR of about 120 pps. Then STRAIGHT was used to generate versions of each syllable for each combination of Ss and Sf in the musical plane. The note corresponding to the original singer is [E, E] on this version of the Ss − Sf plane; so what we refer to as a 'C' is acoustically a 'G' (123 pps). Melody 1 was synthesized with the VTL of the original singer, that is, with notes from the E row of the plane. Melody 2 was synthesized with the VTL of a child, that is, with notes from the upper C row of the plane. Melody 3 was synthesized with a fixed pitch, upper C, and notes from the upper C column of the matrix.
Perceptually, as Melody 3 proceeds and the envelope shifts down by an octave, the child seems to get larger and the voice comes to sound something like that of a counter tenor, that is, a tall person with an inordinately high pitch. The definition of timbre does not say anything specific about how changes in the spectral envelope affect timbre; the acoustic scale variable, Sf, was not recognized when the standard was written. Nevertheless, the definition gives the impression that any change in the spectrum that produces an audible change in the perception of the sound produces a change in timbre, provided it is not simply a change in duration, loudness or pitch, which are all fixed in the current example. Experiments with scaled vowels and syllables show that the just noticeable change in Sf is about 7% for vowels (Smith et al., 2005) and 5% for syllables (Ives et al., 2005), so all but the smallest intervals in the melody would be expected to produce perceptible Sf changes. Since traditionally, voice quality changes are thought to be timbre changes, the perception of the Sf melody in this example seems entirely compatible with the definition of timbre; both voice quality and timbre are changing. However, we are left with the problem that large changes in Ss and Sf both seem to produce changes in voice quality, but whereas the perceptual changes associated with large shifts of the fine-structure along the log-frequency axis are not timbre changes, the perceptual changes associated with large shifts of the envelope along the same log-frequency axis are timbre changes according to the standard. They both produce changes in the relative amplitudes of the spectral components, but neither changes the spectral envelope pattern and neither form of shift alters the libretto.
Melody 4. The problems involved in attempting to unify the perception of voice quality with the definition of timbre become more complex when we consider melodies where both Ss and Sf change as the melody proceeds. Consider the melody produced by co-varying Ss and Sf to produce the notes along the diagonal of the matrix. The musical notation for the melody is shown in Figure 2, Staff (4). The melody is perceived to descend an octave as the sequence proceeds, and there is a progressive increase in the perceived size of the singer from a child to an adult (with one momentary reversal at the start of the second phrase). It is as if we had a set of singers varying in age from 4 to 18 in a row on stage, and we had them each sing their assigned syllable in order, and in time, to produce the melody. The example makes it clear that there is an entire plane of singers with different vocal qualities defined by combinations of the acoustic scale variables, Ss and Sf. The realization that there is a whole plane of voice qualities makes it clear just how difficult it would be to produce a clean definition of timbre that excludes one of the acoustic scale variables, Ss, and not the other, Sf. If changes in voice quality are changes in timbre, then changes in pitch (Ss) can produce changes in timbre. This would seem to undermine the utility of the current definitions of pitch and timbre.
The second dimension of pitch hypothesis
At first glance, there would appear to be a fairly simple way to solve the problem, which is to consider the acoustic scale variable associated with the filter, Sf, to be a second dimension of pitch, which could then be excluded from the definition of timbre along with the first dimension of pitch, Ss. In this case, manipulation of the second dimension of pitch on its own would sound like the change in perception produced by Melody 3 where Ss is fixed at C and Sf decreases by a factor of two over the course of the melody. Semitone changes in the second dimension of pitch, Sf, are unlikely to be sufficiently salient to support accurate reporting of novel melodies (e.g., Krumbholz et al., 2000; Pressnitzer et al., 2001) for which pitch discrimination has to better than about 3%. This second form of pitch is more like the weak pitch associated with a set of unresolved harmonics where pitch discrimination is possible if the changes are relatively large, say 4 semitones. Nevertheless, the second form of pitch would, in some sense, satisfy the ANSI definition of pitch, which says that "Pitch is that attribute of auditory sensation in terms of which sounds may be ordered on a scale extending from low to high." Moreover, it does not seem unreasonable to say that the notes at the start of Melody 3 are higher than the notes at the end, which would support the 'second dimension of pitch' hypothesis.
It does, however, lead to a problem. To determine the pitch of a sound, it is traditional to match the pitch to the pitch or either a sinusoid or a click train. It seems likely that if listeners were asked to pitch match each of the notes in Melody 3, among a larger set of sounds that diverted attention from the orderly progression of Sf in the melody, they would probably match all of the notes to the same sinusoid or the same click train, and the pitch of the matching stimulus would be the upper C. This would leave us with the problem that the second form of pitch changes the perception of the sound but it does not change the pitch (as matched). However, by the current definition, a change in perception that is not a change in pitch (or loudness, or duration) is a change in timbre. Thus, the 'second dimension of pitch' hypothesis would appear to lead us back to the position that changes in Sf produce changes in the timbre of the sound.
It is also the case that the 'second dimension of pitch' hypothesis implies that voice quality changes like those produced by moving around on the musical plane of Figure 3, would be pitch changes rather than timbre changes. And there is one further problem. Many people hear the perceptual change in Melody 3 as a change in speaker size, and they hear a more pronounced change in speaker size when changes in Sf are combined with changes in Ss, as in Melody 4. To ignore the perception of speaker size, is another problem inherent in the 'second dimension of pitch' hypothesis; source size is an important aspect of perception, and pretending that changes in the perception of source size are just pitch changes does not seem like a good idea.
The scale of the filter, Sf, as a dimension of timbre
Rather than co-opting the acoustic scale of the filter, Sf, to be a second dimension of pitch, it might make more sense to consider it as a separable, but nevertheless, internal dimension of timbre - a dimension of timbre that is associated with the perception of voice quality and speaker size. This, however, leads to a problem which is, in some sense, the inverse of the 'second dimension of pitch' problem. Once it is recognized that shifting the position of the fine structure of the spectrum is rather similar to shifting the position of the envelope of the spectrum, and that the two position variables are different aspects of the same property of sound (acoustic scale), then it somehow seems unreasonable to have one of these variables, Sf, within the realm of timbre and the other, Ss, outside the realm of timbre. For example, consider the issue of voice quality; both of the acoustic scale dimensions affect voice quality and they interact in the production of a specific voice quality. Moreover, the scale of the source, Ss, affects the perception of the singer's size, in a way that is similar to the effect of the scale of the filter, Sf. Thus, if we define the scale of the filter, Sf, to be a dimension of timbre, then we need to consider that the scale of the source, Ss, may also need to be a dimension of timbre. After all, large changes in Ss affect voice quality which is normally considered an aspect of timbre. The problem, of course, is that these seemingly reasonable suggestions lead to the conclusion that pitch is a dimension of timbre, which would seem to defeat much of the purpose of defining pitch and timbre in the first place.
The independence of spectral envelope shape
There is one further aspect of the perception of these melodies that should be emphasized, which is that neither of the acoustic scale manipulations causes a change in the libretto; it is always 'pi, pe, ko, kuuu; ni, ne, mo, muuu.' That is, the changes in timbre that give rise to the perception of a sequence of syllables are unaffected by changes in Ss and Sf, even when those changes are large (Smith et al., 2005; Ives et al., 2005). The changes in timbre that define the libretto are associated with changes in the shape of the envelope, as opposed to the position of the envelope or the position of the fine structure. Changes in the shape of the envelope produce changes in vowel type in speech and changes in instrument family in music. Changing the position of the envelope and changing the position of the fine structure both produce substantial changes in the relative amplitudes of the components of the magnitude spectrum, but they do not change the timbre category of these sounds, that is, they do not change the vowel type in speech or the instrument family in music.
Conclusions
Cohen (1993)'s hypothesis that acoustic scale is a basic property of sound leads to the conclusion that the major categories of timbre (vowel type and instrument family) are determined by spectral envelope shape, and that these categories of timbre are relatively independent of both the acoustic scale of the excitation source and the acoustic scale of the resonant filter. In speech, the acoustic scale variables, Ss and Sf, largely determine the voice quality of the speaker, and thus our perception of their sex and size (e.g., Smith and Patterson, 2005). With regard to timbre, this suggests that when dealing with tonal sounds that have pronounced resonances like the vowels of speech, it would be useful to distinguish between aspects of timbre associated with the shape of the spectral envelope, on the one hand, and aspects of timbre associated with the acoustic scale variables, Ss and Sf, on the other hand. This would lead to a distinction between the 'what' and 'who' of timbre, that is, what is being said, and who is saying it. This kind of distinction would at least represent progress towards a more informed use of the term timbre.
Acknowledgements
Research supported by the UK Medical Research Council [G0500221, G9900369].
References
- Cohen, L. (1993). “The scale representation.” IEEE Trans. Sig. Proc., 41, p.3275-3292. [1] [2]
- Fitch, W.T. and Giedd, J. (1999). “Morphology and development of the human vocal tract: A study using magnetic resonance imaging.” J. Acoust. Soc. Am., 106, p.1511-1522. [1]
- Ives, D.T., Smith, D.R.R. and Patterson, R.D. (2005). “Discrimination of speaker size from syllable phrases.” J. Acoust. Soc. Am., 118, p.3816-3822. [1] [2]
- Kawahara, H. and Irino, T. (2004). “Underlying principles of a high-quality speech manipulation system STRAIGHT and its application to speech segregation”, in Speech separation by humans and machines, Divenyi, P.L. editor, p.167-180 (Kluwer Academic). [1]
- Krumbholz, K., Patterson, R.D. and Pressnitzer, D. (2000). “The lower limit of pitch as determined by rate discrimination.” J. Acoust. Soc. Am., 108, p.1170-1180. [1]
- Lee, S., Potamianos, A. and Narayanan, S. (1999). “Acoustics of children's speech: developmental changes of temporal and spectral parameters.” J. Acoust. Soc. Am., 105, p.1455-68. [1] [2]
- Patterson, R.D., Smith, D.R.R., van Dinther, R. and Walters, T.C. (2008). “Size Information in the Production and Perception of Communication Sounds”, in Auditory Perception of Sound Sources, Yost, W.A., Popper, A.N. and Fay, R.R. editors (Springer Science+Business Media, LLC, New York). [1]
- Peterson, G.E. and Barney, H.L. (1952). “Control Methods Used in a Study of the Vowels.” J. Acoust. Soc. Am., 24, p.175-184. [1]
- Pressnitzer, D., Patterson, R.D. and Krumbholtz, K. (2001). “The lower limit of melodic pitch.” J. Acoust. Soc. Am., 109, p.2074-2084. [1]
- Smith, D.R.R., Patterson, R.D., Turner, R.E., Kawahara, H. and Irino, T. (2005). “The processing and perception of size information in speech sounds.” J. Acoust. Soc. Am., 117, p.305-318. [1] [2]
- Smith, D.R.R. and Patterson, R.D. (2005). “The interaction of glottal-pulse rate and vocal-tract length in judgements of speaker size, sex, and age.” J. Acoust. Soc. Am., 118, p.3177-3186. [1]
- Turner, R.E., Walters, T.C., Monaghan, J.J. and Patterson, R.D. (2009). “A statistical, formant-pattern model for segregating vowel type and vocal-tract length in developmental formant data.” J. Acoust. Soc. Am., 125, p.2374-2386. [1] [2] [3] [4]